“当 A 细胞的轴突和 B 细胞足够近,并且重复或不断地对其放电时,A、B 中的一个细胞或者两个细胞都会经历生长过程或者代谢改变,这样 A 细胞(作为对 B 细胞放电的细胞之一)的效率就会得到提高。” 1949 年《行为的组织》 这段话经常被转述成“一起放电的神经元也会被串连在一起”。 赫布理论解释了神经元如何组成联接,从而形成记忆印痕(英语:engram(neuropsychology))。赫布理论阐明了细胞集群(Cell Assemblies)的形态和功能:“两个神经元或者神经元系统,如果总是同时兴奋,就会形成一种‘组合’,其中一个神经元的兴奋会促进另一个的兴奋。如果一个神经元持续激活另一个神经元,前者的轴突将会生长出突触小体(如果已有,则会继续长大)和后者的胞体相连接。” 高尔顿·威拉德·奥尔波特根据自联想 (auto-association) 的思路,进一步提出了关于细胞集群的作用,以及它们在形成记忆痕迹中的角色: 如果系统的输入会导致同样的模式重复出现,那么组成这个模式的元素之间的相互关联性将会大大增强。这意味着,其中任何一个元素都会倾向于触发同组的其他元素,同时(以减少权重的方式)抑制组外其他不相关元素。另一个角度来看,这个模式作为一个整体实现了“自联想”。我们可以把一个学习了(自联想)的模式称为记忆痕迹。 通常认为,从整体的角度来看,赫布学习是神经网络形成记忆痕迹的首要基础。 如今,当突触后神经元在突触前神经元之后会很快放电时,突触会变大(或重新形成突触)。和所有的细胞一样,神经元里外有不同的离子浓度,穿过神经元的细胞膜形成电压。当突触前神经元放电时,微小的囊会向突触间隙释放神经递质分子。这会使突触后神经元的膜中的通道打开,让钾离子和钠离子进入,最终会改变通过膜的电压。如果有足够多的突触前神经元一起放电,电压会突然升高,一个动作电位会顺着突触后神经元的轴突而下。这还会使离子通道变得更加灵敏,并出现新的通道,对突触进行加强。就我们的知识所能达到的水平,这就是神经元进行学习的过程。 感知机是生物神经细胞的简单抽象。神经细胞结构大致可分为:树突、突触、细胞体及轴突。单个神经细胞可被视为一种只有两种状态的机器——激动时为‘是’,而未激动时为‘否’。神经细胞的状态取决于从其它的神经细胞收到的输入信号量,及突触的强度(抑制或加强)。当信号量总和超过了某个阈值时,细胞体就会激动,产生电脉冲。电脉冲沿着轴突并通过突触传递到其它神经元。为了模拟神经细胞行为,与之对应的感知机基础概念被提出,如权量(突触)、偏置(阈值)及激活函数(细胞体)。 在人工神经网络领域中,感知机也被指为单层的人工神经网络,以区别于较复杂的多层感知机(Multilayer Perceptron)。作为一种线性分类器,(单层)感知机可说是最简单的前向人工神经网络形式。尽管结构简单,感知机能够学习并解决相当复杂的问题。感知机主要的本质缺陷是它不能处理线性不可分问题。 在感知器中,一个正权值代表一个兴奋性连接,一个负权值代表一个抑制性连接。如果其输入量的加权和高于界限值,那么会输出 1;如果加权和小于界限值,那么输入 0。通过改变权值和界限值,我们可以改变感知器计算的函数。 输入量的权值越高,相应的突触也会越强。细胞体把所有加权输入量加起来,轴突使结果变成一个阶跃函数。图中代表轴突的框表明了阶跃函数的图像:0 代表输入量的低值,当输入量到达界限值时,会突然变成 1。假设感知器有两个持续输入量 x 和 y(换句话说,x 和 y 可以是任何数值,不仅仅是 0 和 1),那么每个例子都可以由平面上的一个点来表示,而正面例子(例如,感知器中输出量为 1)和负面例子(输出量为 0)之间的界线就是一条直线。 感知器根据所有输入量的权值进行判断,即少数服从多数,通过调整输入量的权值来改进准确性。感知器的缺陷在于感知机不能解决简单的异或(XOR)等线性不可分问题。 S 形曲线是世界上最重要的曲线。首先输出量随着输入量缓慢增长,如此缓慢,似乎保持不变。接着它开始变化得很快,然后变得更快,之后越来越慢,直到几乎保持不变为止。 S 形曲线是所有种类相变的形状:电子应用领域自旋反转的概率、铁的磁化、将少量记忆写到硬盘上、细胞中离子通道的打开、冰块融化、水蒸发、早期宇宙的膨胀扩张、进化中的间断平衡、科学中的范式转移、新技术的传播、离开多民族社区的白人大迁徙、谣言、流行病、革命、帝国的没落等。 当你没法调好淋浴的温度时(开始水很冷,然后很快又变得很热),都是 S 形曲线的错。你做爆米花时,看看 S 形曲线的进度:一开始什么也没发生,几粒玉米爆开,又有一把爆开,很多玉米突然像烟花一样爆开,更多的玉米爆开,最后你就可以吃爆米花了。你肌肉的每个动作都遵循 S 形曲线:先是缓慢移动,然后快速移动,最后又缓慢移动。 如果放大 S 曲线的中段部位,会发现它近似一条直线。很多我们认为是线性的现象,其实都是 S 形曲线,因为没有什么能够毫无限制地增长下去。辨别一条 S 形曲线就会得到一条钟形曲线:缓慢、快速、缓慢变低、高、低。在 S 形曲线加入一连串向上和向下交错的曲线,你会得到接近正弦波的曲线。实际上,每个函数都可以近似看作 S 形曲线的总和:函数上升时,你加一条 S 形曲线;函数下降时,你减掉一条 S 形曲线。孩子的学习也不是一直都处于进步状态,这个过程是若干个 S 形曲线的累积。技术变革也是如此。 反向传播误差误差,通常缩写为「BackProp」,是几种训练人工神经网络的方法之一。这是一种监督学习方法,即通过标记的训练数据来学习(有监督者来引导学习)。 反向传播,比感知器算法要强大很多。单个神经元只能够对直线进行学习。给定足够的隐藏神经,一台多层感知器,正如它的名字一样,可以代表任意的复杂边界。这使得反向传播成为联结学派的主算法。 反向传播是自然及技术领域中非常常见的战略实例:如果你着急爬到山顶,那你就得爬能找到的最陡的坡。这在技术上的术语为“梯度上升”(如果你想爬到山顶)或者梯度下降(如果你想走到山谷)。细菌就是通过游向食物(例如葡萄糖)分子浓度高的地方来觅食的;遇到有毒物质,它们则会游向有毒物质浓度低的地方。所有事物,从机翼到天线阵,都可以通过梯度上升来优化。反向传播就是在多层感知器中有效做到这一点的方法:不断对权值进行微调,以降低误差,然后当所有调整失败时,停止调整。 有了反向传播,你就不必从头开始弄明白怎样对每个神经元的权值进行微调,这样做起来会很慢。你可以一层一层来做,根据调整与其相连神经元的方法,来调整每个神经元。如果在突发事件中,除了一件工具,你得把整个机器学习工具包都扔掉,那么梯度下降可能是你想留下的工具。 梯度下降法背后的直观感受可以用假设情境进行说明。一个被卡在山上的人正在试图下山(即试图找到极小值)。大雾使得能见度非常低。因此,下山的道路是看不见的,所以他必须利用局部信息来找到极小值。他可以使用梯度下降法,该方法涉及到察看在他当前位置山的陡峭程度,然后沿着负陡度(即下坡)最大的方向前进。如果他要找到山顶(即极大值)的话,他需要沿着正陡度(即上坡)最大的方向前进。使用此方法,他会最终找到下山的路。不过,要假设山的陡度不能通过简单地观察得到,而需要复杂的工具测量,而这个工具此人恰好有。需要相当长的一段时间用仪器测量山的陡峭度,因此如果他想在日落之前下山,就需要最小化仪器的使用率。问题就在于怎样选取他测量山的陡峭度的频率才不致偏离路线。 在这个类比中,此人代表反相传播算法,而下山路径表示能使误差最小化的权重集合。山的陡度表示误差曲面在该点的斜率。他要前行的方向对应于误差曲面在该点的梯度。用来测量陡峭度的工具是微分(误差曲面的斜率可以通过对平方误差函数在该点求导数计算出来)。他在两次测量之间前行的距离(与测量频率成正比)是算法的学习速率。 前馈神经网络 前馈神经网络是最先发明也是最简单的人工神经网络。它包含了安排在多个层中的多个神经元(节点)。相邻层的节点有连接或者边(edge)。所有的连接都配有权重。 一个前馈神经网络可以包含三种节点: 在前馈网络中,信息只单向移动——从输入层开始前向移动,然后通过隐藏层(如果有的话),再到输出层。在网络中没有循环或回路(前馈神经网络的这个属性和递归神经网络不同,后者的节点连接构成循环)。 下面是两个前馈神经网络的例子: 多层感知器(Multilayer Perceptron, 缩写 MLP)是一种前向结构的人工神经网络,映射一组输入向量到一组输出向量。MLP 可以被看作是一个有向图,由多个的节点层所组成,每一层都全连接到下一层。除了输入节点,每个节点都是一个带有非线性激活函数的神经元(或称处理单元)。一种被称为反向传播算法的监督学习方法常被用来训练 MLP。MLP 是感知器的推广,克服了感知器不能对线性不可分数据进行识别的弱点。多层感知器(Multi Layer Perceptron,即 MLP)包括至少一个隐藏层(除了一个输入层和一个输出层以外)。单层感知器只能学习线性函数,而多层感知器也可以学习非线性函数。 连接主义学派并不认为人工智能源于数理逻辑,也不认为智能的关键在于思维方式。这一学派把智能建立在神经生理学和认知科学的基础上,强调智能活动是将大量简单的单元通过复杂方式相互连接后并行运行的结果。 基于以上的思路,连接主义学派通过人工构建神经网络的方式来模拟人类智能。它以工程技术手段模拟人脑神经系统的结构和功能,通过大量的非线性并行处理器模拟人脑中众多的神经元,用处理器复杂的连接关系模拟人脑中众多神经元之间的突触行为。相较符号主义学派,连接主义学派显然更看重是智能赖以实现的“硬件”。 参考资料 本文作者:思考问题的熊 版权声明:本博客所有文章除特别声明外,均采用 知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议 (CC BY-NC-ND 4.0) 进行许可。 如果你对这篇文章感兴趣,欢迎通过邮箱订阅我的 「熊言熊语」会员通讯,我将第一时间与你分享肿瘤生物医药领域最新行业研究进展和我的所思所学所想,点此链接即可进行免费订阅。赫布律
感知器
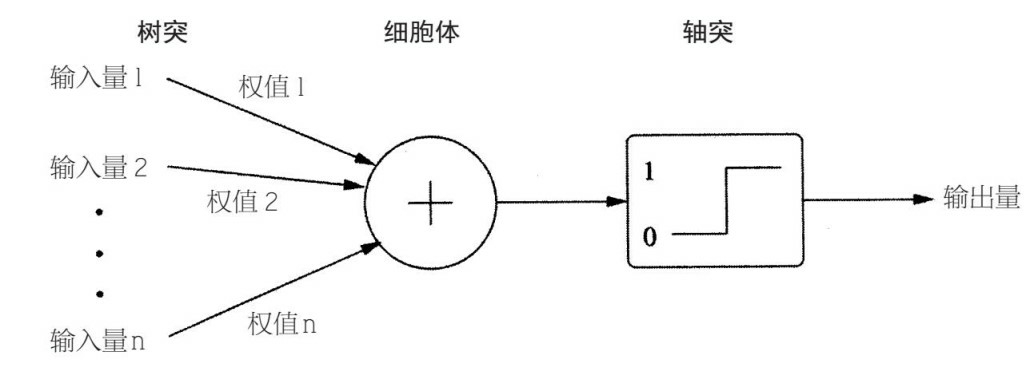
S 形曲线
反向传播和梯度下降
简单说来,BackProp 就像「从错误中学习」。监督者在人工神经网络犯错误时进行纠正。
一个人工神经网络包含多层的节点;输入层,中间隐藏层和输出层。相邻层节点的连接都有配有「权重」。学习的目的是为这些边缘分配正确的权重。通过输入向量,这些权重可以决定输出向量。
在监督学习中,训练集是已标注的。这意味着对于一些给定的输入,我们知道期望 / 期待的输出(标注)。
反向传播算法:最初,所有的边权重(edge weight)都是随机分配的。对于所有训练数据集中的输入,人工神经网络都被激活,并且观察其输出。这些输出会和我们已知的、期望的输出进行比较,误差会「传播」回上一层。该误差会被标注,权重也会被相应的「调整」。该流程重复,直到输出误差低于制定的标准。
上述算法结束后,我们就得到了一个学习过的人工神经网络,该网络被认为是可以接受「新」输入的。该人工神经网络可以说从几个样本(标注数据)和其错误(误差传播)中得到了学习。多层感知器:非线性模型
联结学派
https://www.jiqizhixin.com/articles/2016-11-25-3
· 分享链接 https://kaopubear.top/blog/2018-02-25-TheMasterAlgorithm6/