入门生物信息,所有人都绕不开统计基础知识和相关实现方式。本章我们将简要介绍统计学相关基础知识以及如何使用 R 语言进行简单地计算和分析。 为了解决某个问题,我们通常会观察一组和该问题相关的样本,利用总体中的部分样本来推断总体的情况进而得到相关结论。在通过样本推断总体前,首先需用对已有样本数据进行简单的评估和描述,针对这一需求也就引出了描述统计量这一概念。进行描述性统计时,我们最关注数据两个层面的问题:数据的集中趋势和变异分散性。 面对少则几十多则上千个数字,第一步通常是观察平均水平。下面介绍三个计算数据平均水平的概念:分别是均值 (mean)、中位数 (median) 和众数 (mode)。 均值:所有观察值的和除以观察的个数。算数平均是最自然和常用的测度,其问题在于对异常值 (outliers) 非常敏感。有极端值存在时,均值不能代表样本的绝大多数情况。 中位数:所谓中位数,是指所有样本观测值由小到大排序,位于中间的一个(样本数为奇数)或者两个数据的平均值(样本数为偶数)。 当数据分布对称时,中位数近似等于算数平均数;当数据正倾斜时(图像向右倾斜),中位数小于算数平均数;当数据负倾斜时(图像向左倾斜),中位数大于算数平均数。因此,我们可以通过比较样本的均值和中位数对数据的分布对称性进行初判断。 众数:在样本所有观测值中,出现频率最大(出现次数最多)的数值称为众数。这里需要说明,当数据量很大而且数值不会多次重复出现时众数并不能带来太多信息。比如当计算上万个基因的表达量后,得到的众数最可能是 0,因为每个基因的表达值或多或少都有一些不同,这时候出现最多的就是那些没有检测到表达基因的 0 了。但是在遇到类别数据而非数值型数据时众数有很大用处,或者说众数是唯一可以用于类别数据的平均数。 在 R 中,均值和中位数可以通过 平均数显然不能说明一切问题,在说明样本数据时我们还必须考虑数据是不是过于分散。例如在篮球队员投篮平均得分相同的情况下,更重要的是知道他们谁发挥更加稳定。 极差 (range) 指一个样本中最大值和最小值之间的差值。在统计学中也称为全距,它能够指出数据的“宽度”(范围)。但它和均值一样易受极端值影响,而且也会受样本量明显影响。 针对极差的缺点,统计学又引入分位数 (quantiles) 概念,通俗讲是把数据的“宽度”细分后再去进行比较从而更好地描述数据的分布形态。分位数用三个点将从小到大排列好的数据分为四个相等部分,而这三个点也就是我们常说的四分位数,分别叫做下四分位数,中位数和上四分位数。当然,除了四分位也可以计算十分位或者百分位。 分位数的引进能够说明数值的位置,但无法说明某数值在该位置出现的概率。为了说明数据的稳定程度,我们可以考虑计算每个数据值到平均数的距离(此处可以脑补一个高瘦形的数据曲线和矮胖形的数据曲线),但样本中所有观测值与均值偏差的和永远是 0。为了解决这种正负距离相互抵消的问题,统计学又引入**方差 (variance) 和标准差 (standard deviation) **概念。 所谓方差指数值与均值距离平方数的平均数,而标准差则是方差的平方根。标准差体现了数据的变异度,标准差越小,数值和均值越近。通常均值用表示,而标准差用表示。 在 R 中,可以通过 有了标准差的概念,随之而来的问题是当两个样本标准差相同但是均值相差很大时该如何做出区分。于是,统计学引入了变异系数 (coefficient of variation, CV) 概念,变异系数是指样本标准差除以均值再乘 100%。变异系数不会受数据尺度的影响,因此常用来进行不同样本之间变异性的比较。 在实际的数据分析中,如果要比较不同数据集(均值和标准差都不同)之间的数值,通常会引入** z score **的概念,z score 的计算方法是用某一数值减去均值在除以标准差。通过对原始数据进行 z 变换,我们将不同数据集转化为一个新的均值为 0,标准差为 1 的分布。 在 R 中,使用 下面我们使用 R 中内置的数据** Edgar Anderson's Iris Data **进行一些简单展示。 Sepal.Length Sepal.Width Petal.Length Petal.Width Species 本文作者:思考问题的熊 版权声明:本博客所有文章除特别声明外,均采用 知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议 (CC BY-NC-ND 4.0) 进行许可。 如果你对这篇文章感兴趣,欢迎通过邮箱订阅我的 「熊言熊语」会员通讯,我将第一时间与你分享肿瘤生物医药领域最新行业研究进展和我的所思所学所想,点此链接即可进行免费订阅。写在前面
描述性统计量
数据的集中趋势
mean()和median()进行计算,而众数可以通过modeest包mfv()函数得到。数据的变异性(离散性)
quantile()计算分位数,通过var()来计算方差,通过sd()来计算标准差。计算描述性统计量
summary()函数会得到一个 data frame 的很多 描述性统计量。当数据某一列是数值型变量时,可以得到该列数据的均值、极值、方差和分位数。summary(iris)
#查看常用的描述统计量
Min. :4.300 Min. :2.000 Min. :1.000 Min. :0.100 setosa :50
1st Qu.:5.100 1st Qu.:2.800 1st Qu.:1.600 1st Qu.:0.300 versicolor:50
Median :5.800 Median :3.000 Median :4.350 Median :1.300 virginica :50
Mean :5.843 Mean :3.057 Mean :3.758 Mean :1.199
3rd Qu.:6.400 3rd Qu.:3.300 3rd Qu.:5.100 3rd Qu.:1.800
Max. :7.900 Max. :4.400 Max. :6.900 Max. :2.500### 形象化展示
所谓形象化展示就是用图来展示数据结果,比较常见的方法有条形图,箱线图,直方图等
```r
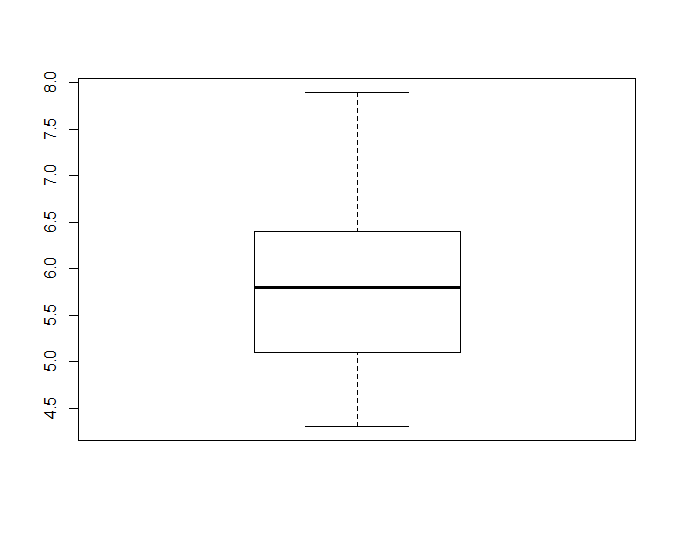
boxplot(iris$Sepal.Length)
# 使用箱线图展示某一列数据的分布情况
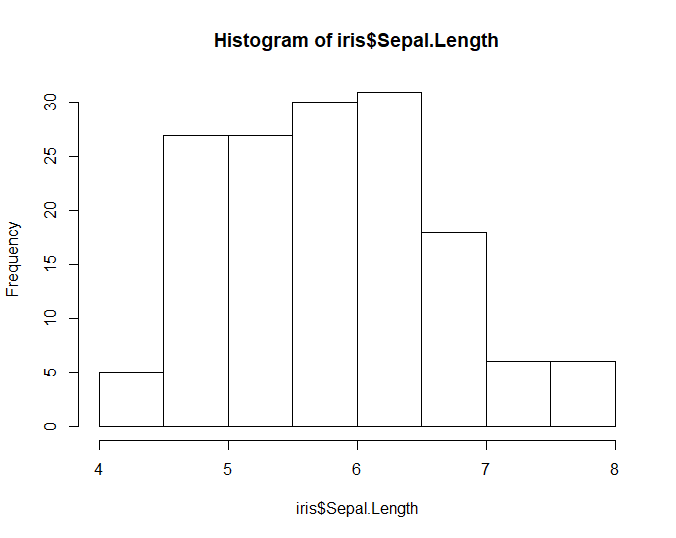
hist(iris$Sepal.Length)
# 使用直方图展示某一列数据的分布情况
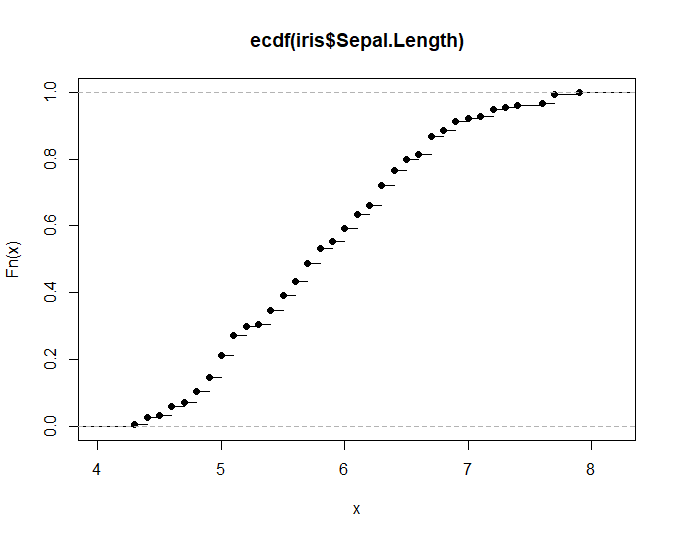
plot(ecdf(iris$Sepal.Length))
# 绘制简单的累积分布函数图展示某一列数据分布情况
· 分享链接 https://kaopubear.top/blog/2017-09-16-RandStatistics1/