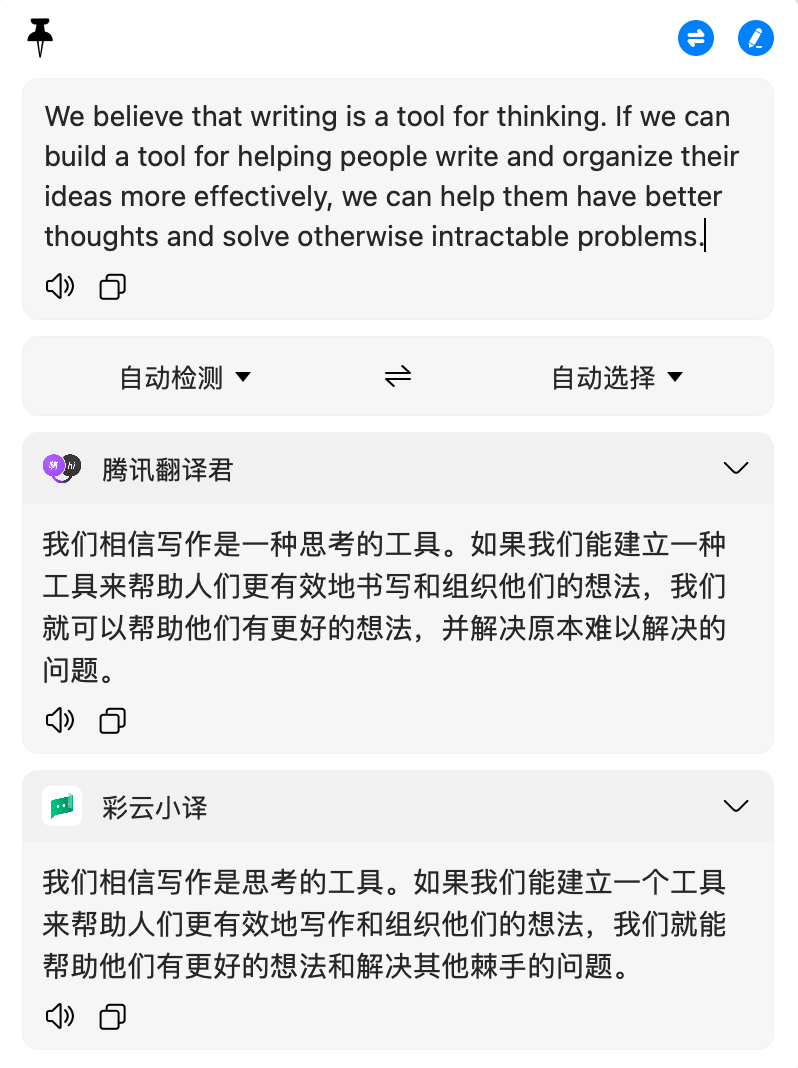
你现在看到的是熊言熊语会员通讯 4321X 的第 1 期试读版本,今后我们会不定期的将部分会员通讯内容发布到公开平台,如果想稳定的阅读每期内容欢迎通过邮件订阅这份免费的会员通讯服务。 Hi, 见信好: 2020 年就要过去了,在未来两三周我们的会员通讯和熊言熊语播客会推出若干期回顾内容,包括播客和书籍 rewind & recommendation 等等,敬请期待。 本期刊首语我们延续上期讨论的问题再聊一聊。上一期我发起的讨论是「读者和作者应该保持一种怎样的关系」。因为上周收到了一封听友来信,这次想用播客主播和听友的关系略加展开。 听友来信的一段内容如下: 听完这期节目,我想把这个节目介绍给我朋友圈所有的人,但是好像我们实验室只有我一个人在努力开创生信的领域,无人分享这种快乐。听了你们的思考,我甚至觉得我可以把你们当做我的朋友,一个向我传输观点,我只需要静静聆听即可的朋友了。 播客是少有的可以在闭屏环境下接受信息的渠道,文章和视频都需要我们开着屏幕阅读和观看。闭屏场景又通常发生在通勤、做家务和睡前等时段,是一个相对私密的时间,因此听友和主播也更容易建立起信任感,像来信里提到的「可以当做朋友」。 这个优势带来一个问题是不少听友会有一种想要「私藏」播客的感觉,像邮件里提到只是静静聆听,其实每一个内容创作者都需要也希望内容可以被更多人看到。还有一种情况是不少人觉得这节目收听的人不少,肯定也不缺我一个留言不缺我一个转发,但真相是你的一次留言和推荐很可能就是作者坚持更新的动力和鼓励。 推荐带来的是整体收听量和阅读量的增加,也就是内容整体影响的感知;留言带来的是明确的信息传达结果的反馈。这两点对于内容创作者实在是太重要了,所以如果你有喜欢的博客播客或者作者,尽可能地去和他们沟通,也把你喜欢的内容推荐给朋友。 他们缺的,就是你的一次留言和一次推荐。 We describe popular multi-omics data integration approaches used to identify target genes and co-factors, and we discuss how machine learning techniques may predict transcriptional regulators and gene expression. DOI:https://doi.org/10/gg9zxf 转录调控是一个经久不衰的研究话题,如果归结到测序技术使用最多的就是 RNA-seq 和 ChIP-seq,他们也是学习生物信息分析的基本路径。这两个技术结合可以涉及到大量相关研究问题,例如鉴定相互作用的调控因子和表观调控因子,鉴定靶基因、预测基因表达还可以预测转录因子结合。这篇综述就从这些层面进行了介绍,比较适合想大致了解一个相关框架的情况下阅读。 Here we present an overview of the computational workflow involved in processing scRNA-seq data. We discuss some of the most common tasks and the tools available for addressing central biological questions. In this article and our companion website (https://scrnaseq-course.cog.sanger.ac.uk/website/index.html), we provide guidelines regarding best practices for performing computational analyses. DOI:https://doi.org/10/ghn48p 谈到转录组分析学习,颇有几篇值得参考的经典文献。Nature Protocols 最近发布的这篇单细胞测序分析指南颇有几分类似的潜质,感觉有可能成为单细胞分析学习必读的一篇经典文献,和文章配套的还有一个更加详细的在线教程。如果你正在学习单细胞数据分析,这篇文献推荐给你。 Here, we develop VarNote to rapidly annotate genome-scale variants in large and complex functional annotation resources. Equipped with a novel index system and a parallel random-sweep searching algorithm, VarNote shows substantial performance improvements (two to three orders of magnitude) over existing algorithms at different scales. It supports both region-based and allele-specific annotations, and introduces advanced functions for the flexible extraction of annotations. DOI:https://doi.org/10/ghmqdt 如果问生物信息的日常工作是什么,我目前能想到两个层面:一个是进行各种文件格式的转换,一个就是求各种区间的交并集。变异注释归根结底还是一个求区间交并集的问题,这个事情看起来简单,但处理大量数据集的时候就会变得异常缓慢,常用的 bedtools 很难解决问题,特别是集成到网站服务的时候让别人等个七八分钟很不合时。这篇文章作者开发了一个针对大数据集进行变异数据的工具,并且和其它工具进行了准确度和速度的比较。如果你有被类似的速度问题所困惑,推荐使用。 We integrated 24 data sources to develop a standardized collection of 2.4 million regulatory elements in the human genome, transcription factor binding sites, DNase peaks, ultra-conserved non-coding elements, and super-enhancers. Information on controlled gene(s), tissue(s) and associated phenotype(s) are provided for regulatory elements when possible. We also calculated a variation constraint metric for regulatory regions and showed that genes controlled by constrained regions are more likely to be disease-associated genes and essential genes from mouse knock-out screenings. DOI:https://doi.org/10.1101/2020.09.17.301960 各种调控和表观相关的数据如何应用到突变注释已经有了一些相关的文献报道,这篇最近发布在预印本上的文章同样是关注的这个问题。作者们把人类表观调控相关的数据能整合的全部整合了,在构建一个数据库的基础上也开发了一个注释工具。如果你想看看自己的突变数据和这些表观调控元件之间的关系,这篇文章推荐给你。 我们应该如何保护或者管理自己的数字资产,以及我们应该如何理解自己的数字权利呢? 上周我收到了一封 Google 的邮件,他们更新了数据存储政策。邮件开头的一句话是「我们近期公布了关于存储空间的新政策,以确保符合行业惯例」,言外之意就是「同行都这么做」。 存储新政策主要内容有两点: 这封邮件引发了我的一些思考,因为我并不仅使用 Apple 的设备,所以近 5 年的照片全都存储在 Google Photos,他们的存储政策经历过几次变化,从之前的高清图(略有压缩)无限存储到所有图片都不会无限存储,再到如今的不活跃账户或者超限额内容将会直接删除。你有没有想过什么情况下会连续 2 年不使用某一个产品呢?其实每个人都会遇到的一个情况,就是当我们离开这个世界以后。 或许很快,数字遗产会和实体一样成为每个人都必须要面对的议题。谈遗产有点远,你有没有考虑过自己的数字资产问题呢?很多看不见摸不着的东西对我们越来越重要,比如你的各种社交平台账号,写的文章,录制的播客和上传的视频,以及在你电脑里各种各样的文件。没有这样的意识就很可能会经历硬盘损坏和数据丢失的悲剧,吊诡的是通常只有经历过刻骨铭心的数字资产丢失,才能理解备份的重要。 安全意识的增强使越来越多的人开始接触和使用云存储,不过云存储依旧是等于你租了一块在千里之外的硬盘用来保存自己的数字资产。云存储并不是绝对安全的,这样的例子发生过不少,有的人相信云存储,有的人不相信。此外,有些东西一旦被存储到云上可能就不属于你或者不仅仅属于你了,它可能随时被删除或者永远也不会被删除。 如果你认为购买过的软件和数据是属于你的,那也有些天真,如今我们通常只拥有很多东西的读取资格而没有操作资格。 靠谱的云服务是看来相对安全的选择,因为你已经使用了很多年的云笔记和云存储服务,但时间尺度如果拉长到十年二十年,这些公司可能会倒闭可能变得越来越难用,我们又该怎么办呢。 对了,关于备份数据有一个3-2-1 原则,你可以参考。 3:保留至少三个数据副本 扩展阅读 data backup options 价格很大程度上不取决于工作成本,而是取决于购买的东西对你多有用。 这个思考的来由还是和数据存储有关,一个朋友用了很久的硬盘突然坏了然后问我的建议,只能让他找一家数据修复的公司去碰碰运气。几天后他和我说:公司可以恢复 99%的数据,但是要价 2600,以你的经验,这个可以讲价到低一点,因为总感觉他们没有这么高的工作成本。 我给出的回复是:2600 要比较的不是我们推断的公司工作成本,而是自己的数据值不值 2600。即便他们就是用 1 秒钟点了下某个一键恢复软件,如果这些数据是你急需且重要的,那 2600 也得花啊。 当然,上面的回答并不符合标准的经济学对于成本的解释,还需要考虑显性成本隐形成本沉默成本和机会成本以及所谓的稀缺性。成本是复杂的,不仅仅是购买生产要素的货币支出或者提供服务的人付出了多少工作,而是在于被多少人需要或对够买的人多么重要。我们可以坦然的接受便利店的东西比大型超市稍微贵一些,iPhone 的定价远高于所有物料价格的总和,很多非实体的服务同样如此。 产品价格与成本无关,价供求关系决定了商品的价格,甚至这个价格反过来决定了原材料的成本,比如 2020 年的口罩价格变化。 只关注两类人的情绪和感受,一类是给你爱的人,一类是给你钱的人。 我是一个情绪比较容易受外界影响的人,也总是努力让更多人对我的所作所为感到满意。但最近播客听友群里一个听友的催更行为让我感到冒犯和不舒服,也开始反思更应该关注哪些人的情绪和感受。 我不反对催更,很多时候就是善意的调侃同时告诉你有人在等着听节目,但单纯的催更绝对不会成为更新的动力,参与和讨论才是。他在群里参与互动的唯一形式就是催更,同一句话反复催更。节目更新前的催促和节目更新后的沉默形成了鲜明的对比,或许催更才是他最大的乐趣吧。 我尝试用戏谑的方式和他「正面交锋」,比如他的 ID 是催更小助手,我就改成反催更,更新了群公告,准备了最新回复话术,类似反问实验做了么文章发了么论文写了么工作找了么结婚了么等等。甚至,我计划连续七天每天更新一分钟的音频,专门反问那些无聊的问题发给他听。 在脑海中反复交战几个回合平静以后,我把自己逗笑了。何必呢,倘若催更能让他开心一些,也挺好。我们需要做的就是尽量只关注两类人的情绪和感受,一类是给你爱的人,一类是给你钱的人。前者包括父母家人和最紧密的朋友,因为他们难受你也难受;后者包括你的老板导师客户以及其他购买了你时间和生产力的人,因为他们难受你就饿肚子。如果还有剩余精力就多多关注自己。 上一期工具推荐提到了 Mac 上的一个小工具 PopClip,这次推荐一个可以配合 PopClip 使用的翻译工具 Bob。 Bob 是一款 Mac 端翻译软件,支持划词翻译、截图翻译以及手动输入翻译。可以进行翻译多开和自定义若干翻译插件,可以通过 AppleScript 调用和 PopClip 调用。 Bob 本身是不收费的,但使用某些服务可能需要给服务商支付一定的费用。经过测试,我目前保留的是腾讯翻译君和彩云小译的翻译 API,前者每月有 500 万字符的免费额度后者则有 100 万字符的免费额度,正常使用应该足够。OCR 识别用的是腾讯云通用 OCR,每个月有 1000 次免费额度。 服务需要配置但难度并不大,尤其是当你还在使用腾讯云的其他产品时,翻译和 OCR 服务只需开启然后在 Bob 配置秘钥即可。 使用效果如下图,详细的配置教程可以访问官网。 Zotero 一直我最推荐的文献管理工具,关于 Zotero 的基本用法可以参考我曾经发在少数派的Zotero 上手指南,目前这篇文章的阅读量已经超过了 11 万。其实跳脱出文献管理,Zotero 配合浏览器插件基本可以用来保存万物,然后可以对万物添加标签和笔记进行管理。例如如果你单纯保存一个网页,Zotero 可以对网页内容生成快照在本地保存一个 HTML 文件。 关于 Zotero 的优点,曾经整理过如下几个: 我曾经修改过一个支持 markdown 格式笔记的插件,最近又用上了一个很棒的 Zotero markdown 相关插件zotero-mdnotes,它可以把文献条目的元信息和已有笔记都转换为 markdown 格式文件,方便进一步整理,如果你有类似的需求,推荐使用。 本期通讯,我想和你讨论的话题是:有什么事情你曾经会刻意做但现在不会了,又是为什么呢? 我可以先分享一个。 之前通勤坐地铁我会刻意避开早高峰,比如要求自己 7 点半之前必须出门,起晚了就 9 点再出门,但是现在不会了。我发现永远不知道哪个时间是真的高峰,有时在最拥挤的时间段会来一辆人并没有那么多的车,而且,看起来已经满了的地铁到了下一站永远都可以再挤进来几个人。 欢迎回复邮件 [email protected] 2020 年接近尾声,真是复杂而疯狂的一年。端传媒近日发布了一篇题为「2020 年,网络流行语里的中国」回顾文章。作者盘点了 2020 年 14 个互联网流行语,借此回看这颠簸的一年,并试图理解流行语背后的社会脉络。因为是一篇有付费墙的文章所以我只把关键词贴在这里,希望可以帮你回忆一些很快就又会被遗忘的事情。 本文作者:思考问题的熊 版权声明:本博客所有文章除特别声明外,均采用 知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议 (CC BY-NC-ND 4.0) 进行许可。 如果你对这篇文章感兴趣,欢迎通过邮箱订阅我的 「熊言熊语」会员通讯,我将第一时间与你分享肿瘤生物医药领域最新行业研究进展和我的所思所学所想,点此链接即可进行免费订阅。
我是思考问题的熊,你现在正在阅读的是熊言熊语会员通讯「4321X」第 1 期。
截至本期通讯,「4321X」订阅人数为:304。刊首语
文献
Seq-ing answers: Current data integration approaches to uncover mechanisms of transcriptional regulation
Tutorial: guidelines for the computational analysis of single-cell RNA sequencing data
Ultrafast and scalable variant annotation and prioritization with big functional genomics data
GREEN-DB: a framework for the annotation and prioritization of non-coding regulatory variants in whole-genome sequencing
思考

2:并将两个备份副本存储在不同的存储介质上
1:其中一个副本应该位于异地。
推荐
翻译软件 Bob
保存万物的文献管理工具 Zotero
讨论
one more thing
· 分享链接 https://kaopubear.top/blog/2020-12-13-4321x-1/