在 Linux 中跑各种任务或者循环命令的时候,有一个高频的需求是截取一部分文件名。例如有文件 XXX_aaa.bb 和 YYY_aaa.bb ,很可能我们需要提取出 XXX 和 YYY 来给后续的文件进行命名。 实现这个需求的方法有不少。 利用变量中的 % 号。在 Linux 中使用百分号将变量的内容从变量的尾部删除。 一个%号可以从尾部最近位置进行匹配删除,两个%%从尾部最远位置匹配删除。同时支持使用通配符。例如 第二种方式是使用 cut 第三种是使用 awk,和 cut 类似也是指定分隔符输出第一列 为了让脚本使用率更高一些,我通常会使用绝对路径来指定文件位置。为了更快的获取文件名,会使用命令 basename。basename 本身就有一个非常好用的功能,可以剔除指定的文件名结尾部分。如下所示,我觉得这个应该是最优雅的方式。 场景如下,现在有好几百个文件需要重命名。类似于 A1.txt A1.md A1.pdf B2.txt B2.md B2.pdf ... 昨天在知识星球抛出这个问题之后有几个小伙伴给出了自己的建议,其中给我最大冲击的是一个小伙伴提出的 Excel 批量法,思路是用 Excel 对字符段组合出新的命令。 这个需求或许可以拆解为两个问题,一个是重命名,一个是批量。 重命名的方法 mv 或者 rename 都可以,批量很容易想到 for 循环,因为对应的一对变量已经在文件的一行了,所以只要把它们分别保存为两个变量就好了。这个需求更好的完成是方式是配合 while 和 read 来完成循环。 因此可以写为: 如果把这个小小的命令变成一个 rename.sh 脚本,可以写成。 多说一句,关于理解 read 的用法,有一个小的测试题。 上面这个命令,请问输出的结果是什么?是 3 2 1 6 5 4 么?如果不是又会是什么呢?如果能直接说出 3 4 5 6 2 1 这个结果,应该就是理解了。 这个需求也比较常见,在 Linux 中,不能的目录下都有可能存在相同的文件名,例如有些生信分析软件跑多套数据,通常只会在目录层面进行区分,而不会在文件名层面进行区分。可能的目录结果如下: 为了方便处理,我们通常习惯把同一个类型的文件放在一起,但是如果直接拷贝源文件,会因为文件名重复的问题带来灾难。这时就有了一个重命名再拷贝的问题。 重命的一个基本思路就是把需要的目录名加到源文件名字的前面或者后面。首先拿到实际的文件名可以使用 basename 命令,如果想拿到目录名则可以使用 dirname 命令。 本文作者:思考问题的熊 版权声明:本博客所有文章除特别声明外,均采用 知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议 (CC BY-NC-ND 4.0) 进行许可。 如果你对这篇文章感兴趣,欢迎通过邮箱订阅我的 「熊言熊语」会员通讯,我将第一时间与你分享肿瘤生物医药领域最新行业研究进展和我的所思所学所想,点此链接即可进行免费订阅。去除文件名后缀
id=XXX_aaa.bb 可以使用 ${id%%_*}cut -d ‘_’ -f 1。使用 _ 作为分隔符,输出第一列,也是可以得到 XXXls *.bb| awk -F "_" '{print $1 }'basename /a/b/c/XXXX_aaa.bb _aaa.bb
XXXX
批量重命名
其中 A1 要全部替换为 C3 ,B2 要全部替换为 D4 变为,即 C3.txt C3.md C3.pdf D4.txt ...
已经有一个两列的文件是对应信息。A1 C3
B2 D4
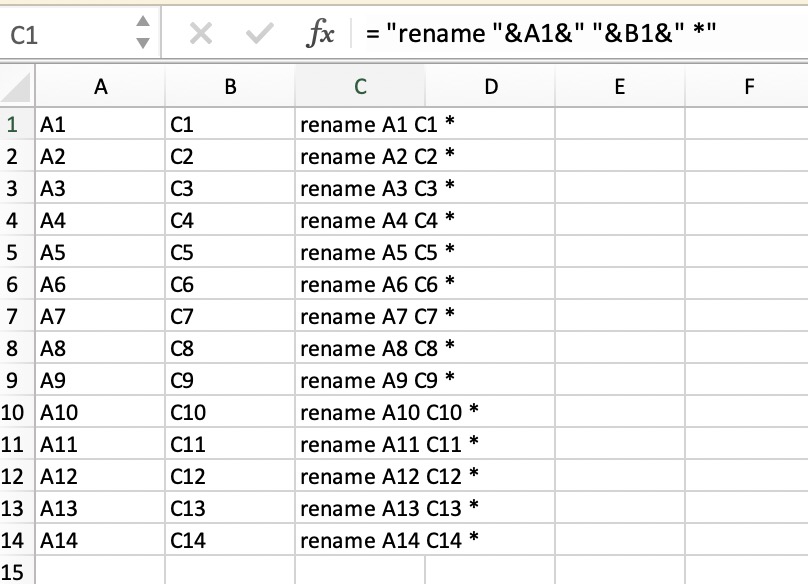
read 可以从标准输入或者管道以及文件描述符读取内容,而且非常方便的可以直接定义多个变量。while read old new
do
echo $old $new;
rename "s/${old}/${new}/" ${old}*
done<changename.txt
#!/bin/bash
FILE=$1
while read old new
do
echo $old $new;
rename "s/${old}/${new}/" ${old}*
done < $FILE
echo '1 2 3 4 5 6' | while read a b c
do
echo $c $b $a
done
同文件名文件拷贝
a: xx.txt yy.json zz.bam
b: xx.txt yy.json zz.bam
for i in `ls */*.bam`
do
cp $i ./bamfile/$(dirname $i)_$(basename $i)
done
· 分享链接 https://kaopubear.top/blog/2020-05-30-linuxfile3tips/