什么时候写 csvtk 呀,csvtk 也借鉴了些 datamash 的东西。 之前写 datamash 的使用教程,收到了一位读者的私信,内容如上。 话说这位读者不是别人,正是大名鼎鼎 seqkit 和 csvtk 的开发者 shenwei356 (github ID),江湖人称「爪哥」。我从来没有问过他为什么 ID 有个数字后缀「356」,我私以为是一年 365 天里有 356 天他都在写程序,剩下的几天过年放假。说到爪哥,如果你看到这篇文章之前不知道他我不怪你,但是今天以后希望他可以每天都和你在一起。 爪哥用两个工具就让自己在生物信息领域有了一席之地。其中 seqkit 是用来处理 fasta/q 文本的工具,这篇文章要写的 csvtk 是处理 c/tsv 文本的工具。如果你感觉我的说法夸张了,不妨想想每天接触到的各种文件,无论是 gff 还是 bed 还是 sam 甚至是 vcf,其本质都是 tsv 格式,再加上 seqkit 针对的 fasta 和 fastq。如果你能熟练使用这两个工具,今后的每一天就都会感受到爪哥无微不至的关怀。我经常在敲完一行命令后会在心里大喊一声「爪哥 NB」。 熟悉 Linux 的人谈到命令行的文本处理,定会奉上文本处理「三剑客」:awk,sed,grep。csvtk 并不想抢他们的风头,而是可以无痛的整合到各种处理流程中。它凭借自己的特点,让命令行里的文本处理更容易。 csvtk 的特点之一是对 header 的识别和处理,它可以让你省去很多原本在使用 awk 等命令时针对 header 行的代码。既然考虑到了 header,特点之二就是支持通过列名来进行列的选择,这里的选择还包括反选和模糊选择。除此之外,之所以说便于和其他流程的整合,还因为它可以直接处理标准输入和压缩文本,同时这个软件本身不需要编译也没有任何其它依赖,非常容易安装,conda 可以直接搞定。 csvtk 本身支持多线程以及若干子命令,用起来会发现通常其速度和效率比在 python 和 R 中输入很多行代码都要高。如果这些依旧不能打动你,csvtk 还有一个神奇的功能:直接用一行代码在命令行里画图。真 6。 csvtk 有三十多个子命令,基本上可以理解为是命令行版极简 dplyr 加若干 linux 命令的增强整合。子命令按照类别和功能分类,可以分为如下几类,其中结尾带有 这一类命令是操作的重点,有很多子命令,其中部分类似于 unix 中对应的命令但又有所区别。 如果你熟悉 R 中的 dplyr,这类型的子命令中有不少都会让你感觉熟悉。 借助 gonum 中的 plot 包,csvtk 还可以直接画一些基本的统计图,这功能其实已经超越 dplyr 向着 ggplot2 挺进了。画图相关命令可以根据文件后缀自动确定输出类型。 plot 支持 boxplot, histogram, line 和 scatter 四种图,图的主要元素都可以设置,支持的输出格式包括 eps/pdf/svg/tiff/jpg/png,对应如下三个命令: 因为篇幅的原因,这里仅展示几个使用示例,更多更详细的内容可以直接参考爪哥写的使用文档。另外本文使用的数据也来自官方测试数据。 csvtk 的 针对上述数据,按照第一列和第二列进行分组,同时计算第四列和第五列的和,排除非数值内容,以易读方式输出结果。命令如下: 上面已经用到的 之前曾经讨论一个大文本去重的问题,从当时的结果来看,对于大文本在 linux 中排序是去重的主要限速步骤。但是在 csvtk 中,可以不通过排序而直接进行去重。针对当时的问题,对于一个 3,741,430 行的文本,先排序再去重需要 30s 左右的时间,而使用 csvtk uniq 仅需要两三秒。 csvtk 中的 使用 比如拼接字符串: 甚至还可以通过三元运算符进行判断填空: 在测试数据中,有一组数据包含不同组别的序列长度和 GC 含量,可以通过 文末还是要说回开发者。爪哥是一个非常勤奋的人,可以看看他的 GitHub,嗯,真绿。csvtk 最近一次 commit 是在 8 天前,seqkit 最近一次 commit 也是在 8 天前。 所以,如果你在使用过程中有什么问题和需求,不妨去给他提几个 issue,没准他一顺手就实现了你的想法。 本文作者:思考问题的熊 版权声明:本博客所有文章除特别声明外,均采用 知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议 (CC BY-NC-ND 4.0) 进行许可。 如果你对这篇文章感兴趣,欢迎通过邮箱订阅我的 「熊言熊语」会员通讯,我将第一时间与你分享肿瘤生物医药领域最新行业研究进展和我的所思所学所想,点此链接即可进行免费订阅。写在前面
csvtk 特点
csvtk 介绍
+的子命令是我常用的和值得尤其关注的。文本信息类
headers 打印首行(列名)dim 查看文件的行列数 ,和 R 中的 dim 类似 +summary 对所选列进行简单的描述性统计,如果是统计内容是数字,则类似于 R 中的 summary() ,同时支持分组统计。如果统计内容是文本,支持类似于 datamash 的多内容统计。+格式转化类
pretty 可以让 csv 变成漂亮的对齐易读表格+transpose 类似于 R 中的t()对数据进行转置csv2json 则可以让数据转换为 json 格式csv2md 则是炫酷的直接变成 markdown 支持的表格+集合操作类
head 查看文件开始若干行concat 合并文件,类似于cat但是可以按照列名进行匹配合并sample 按照比例对文本进行提取cut 按照列选择,支持列数和列名,支持反选和模糊选择+uniq 无需排序进行去重+freq 所选字段评率统计inter 多个文件取交集grep 类似于 lunix 的 grep,支持正则和反选等操作+filter 按照数学表达式筛选,支持多列判断,精简版filter2 按照数学表达式筛选,约等于 lunix 中的 awk,复杂版+join 按照字段合并多个文件,类似于 linux 的 joinsplit 按照某列值拆分文件,也就是分组保存为多个文件collapse 按照所选字段的 key 合并其它字段+文本编辑类
add-header 增加列名del-header 删除列名rename 对列重命名rename2 支持正则表达式的列重命名replace 通过正则表达式替换所选列对应的内容,支持捕获变量,内置特殊替换符号+mutate 对某一列进行正则表达处理增加新的一列mutate2 对多列进行 awk 类似的字符和数学表达式处理,增加新列+gather 类似于 dplyr 中的gather()函数,数据「由宽变长」sort 支持按照一列或者多列排序,且支持自定义顺序排序画图
csvtk plot histcsvtk plot boxcsvtk plot linecsvtk 示例
描述统计量
summary 命令有两个亮点,第一是支持对文本和数值的多种分组统计;第二个是可以过滤对应字段的非数值内容(比如N/A)。$ cat digitals2.csv
f1,f2,f3,f4,f5
foo,bar,xyz,1,0
foo,bar2,xyz,1.5,-1
foo,bar2,xyz,3,2
foo,bar,xyz,5,3
foo,bar2,xyz,N/A,4
$ cat digitals2.csv | \
csvtk summary -i -f f4:sum,f5:sum -g f1,f2 | \
csvtk pretty
f1 f2 f4:sum f5:sum
bar xyz 7.00 106.00
bar xyz2 4.00 4.00
foo bar 6.00 3.00
foo bar2 4.50 5.00
一键变漂亮
pretty命令可以让输出的结果更加易读。$ cat names.csv
id,first_name,last_name,username
11,Rob,Pike,rob
2,Ken,Thompson,ken
4,Robert,Griesemer,gri
1,Robert,Thompson,abc
$ cat names.csv |csvtk pretty
id first_name last_name username
11 Rob Pike rob
2 Ken Thompson ken
4 Robert Griesemer gri
1 Robert Thompson abc
$ cat names.csv |csvtk pretty -r
id first_name last_name username
11 Rob Pike rob
2 Ken Thompson ken
4 Robert Griesemer gri
1 Robert Thompson abc
无需排序快速去重
time awk 'OFS="\t" { if($1>$2){print $2,$1,$3} else {print} }' howtouniq.txt \
| csvtk uniq -H -t -f 1,2 > howtouniq.txt.awk-csvtk
#real 0m2.674s
#user 0m5.660s
#sys 0m0.482s
复杂条件筛选数据
filter2 支持使用复杂条件筛选数据,类似于 awk。首先支持 + - / * & | ^ ** % 等运算,也支持> >= < <= == != =~ !~,同时还可以使用|| && 对多个条件进行组合。例如:
$ cat names.csv
id,first_name,last_name,username
11,"Rob","Pike",rob
2,Ken,Thompson,ken
4,"Robert","Griesemer","gri"
1,"Robert","Thompson","abc"
NA,"Robert","Abel","123"
$ cat names.csv | csvtk filter2 -f '$id > 3 || $username=="ken"'
id,first_name,last_name,username
11,Rob,Pike,rob
2,Ken,Thompson,ken
4,Robert,Griesemer,gri
快速添加新列
mutate2可以按照复杂运算快速添加新的内容,支持的操作和filter2一致。$ cat names.csv \
| csvtk mutate2 -n full_name -e ' $first_name + " " + $last_name ' \
| csvtk pretty
id first_name last_name username full_name
11 Rob Pike rob Rob Pike
2 Ken Thompson ken Ken Thompson
4 Robert Griesemer gri Robert Griesemer
1 Robert Thompson abc Robert Thompson
NA Robert Abel 123 Robert Abel
cat digitals.tsv | csvtk mutate2 -t -H -e '$1 > 5 ? "big" : "small" '
4 5 6 small
1 2 3 small
7 8 0 big
8 1,000 4 big
单行命令快速出图
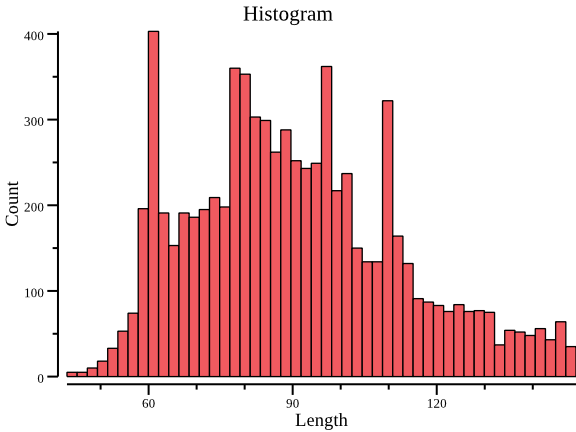
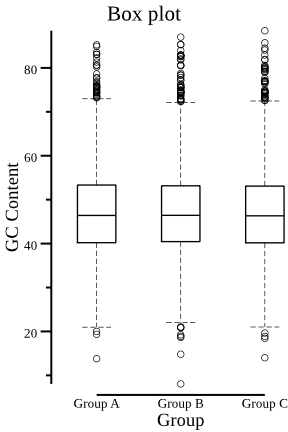
plot hist绘制长度的直方图,通过plot box绘制每组的 GC 含量箱线图。
$ zcat grouped_data.tsv.gz | head -n 5 | csvtk -t pretty
Group Length GC Content
Group A 97 57.73
Group A 95 49.47
Group A 97 49.48
Group A 100 51.00
csvtk -t plot hist grouped_data.tsv.gz -f 2 --title Histogram -o histogram.png
csvtk -t plot box grouped_data.tsv.gz -g "Group" -f "GC Content" --width 3 --title "Box plot" > boxplot.png
one more thing
· 分享链接 https://kaopubear.top/blog/2019-06-28-csvtkbasic/